22. 生成器
- 22.1. 概述
- 22.1.1. 什么是生成器?
- 22.1.2. 生成器的种类
- 22.1.3. 用例:实现可迭代对象
- 22.1.4. 用例:更简单的异步代码
- 22.1.5. 用例:接收异步数据
- 22.2. 什么是生成器?
- 22.2.1. 生成器的作用
- 22.3. 作为迭代器的生成器(数据生产)
- 22.3.1. 迭代生成器的方式
- 22.3.2. 从生成器返回
- 22.3.3. 从生成器抛出异常
- 22.3.4. 示例:迭代属性
- 22.3.5. 只能在生成器中使用
yield - 22.3.6. 通过
yield*进行递归
- 22.4. 作为观察者的生成器(数据消费)
- 22.4.1. 通过
next()发送值 - 22.4.2.
yield绑定松散 - 22.4.3.
return()和throw() - 22.4.4.
return()终止生成器 - 22.4.5.
throw()表示错误 - 22.4.6. 示例:处理异步推送的数据
- 22.4.7.
yield*:完整的故事
- 22.4.1. 通过
- 22.5. 作为协程的生成器(协作式多任务处理)
- 22.5.1. 完整的生成器接口
- 22.5.2. 协作式多任务处理
- 22.5.3. 通过生成器进行协作式多任务处理的局限性
- 22.6. 生成器示例
- 22.6.1. 通过生成器实现可迭代对象
- 22.6.2. 用于惰性求值的生成器
- 22.6.3. 通过生成器进行协作式多任务处理
- 22.7. 迭代 API 中的继承(包括生成器)
- 22.7.1.
IteratorPrototype - 22.7.2. 生成器中
this的值
- 22.7.1.
- 22.8. 样式考虑:星号前后空格
- 22.8.1. 生成器函数声明和表达式
- 22.8.2. 生成器方法定义
- 22.8.3. 格式化递归
yield - 22.8.4. 记录生成器函数和方法
- 22.9. 常见问题解答:生成器
- 22.9.1. 为什么使用关键字
function*表示生成器而不是generator? - 22.9.2.
yield是关键字吗?
- 22.9.1. 为什么使用关键字
- 22.10. 总结
- 22.11. 延伸阅读
22.1 概述
22.1.1 什么是生成器?
可以将生成器视为可以暂停和恢复的进程(代码段)
function* genFunc() {
// (A)
console.log('First');
yield;
console.log('Second');
}
请注意新语法:function* 是 _生成器函数_ 的新“关键字”(还有 _生成器方法_)。 yield 是一个运算符,生成器可以使用它暂停自身。此外,生成器还可以通过 yield 接收输入和发送输出。
调用生成器函数 genFunc() 时,会得到一个 _生成器对象_ genObj,可以使用它来控制进程
const genObj = genFunc();
该进程最初在 A 行暂停。 genObj.next() 恢复执行,genFunc() 中的 yield 暂停执行
genObj.next();
// Output: First
genObj.next();
// output: Second
22.1.2 生成器的种类
生成器有四种
- 生成器函数声明
function*genFunc(){···}constgenObj=genFunc(); - 生成器函数表达式
constgenFunc=function*(){···};constgenObj=genFunc(); - 对象字面量中的生成器方法定义
constobj={*generatorMethod(){···}};constgenObj=obj.generatorMethod(); - 类定义(类声明或类表达式)中的生成器方法定义
classMyClass{*generatorMethod(){···}}constmyInst=newMyClass();constgenObj=myInst.generatorMethod();
22.1.3 用例:实现可迭代对象
生成器返回的对象是可迭代的;每个 yield 都会贡献于迭代值的序列。因此,可以使用生成器来实现可迭代对象,这些对象可以被各种 ES6 语言机制使用:for-of 循环、展开运算符 (...) 等。
以下函数返回一个对象的属性的可迭代对象,每个属性对应一个 [键,值] 对
function* objectEntries(obj) {
const propKeys = Reflect.ownKeys(obj);
for (const propKey of propKeys) {
// `yield` returns a value and then pauses
// the generator. Later, execution continues
// where it was previously paused.
yield [propKey, obj[propKey]];
}
}
objectEntries() 的使用方法如下
const jane = { first: 'Jane', last: 'Doe' };
for (const [key,value] of objectEntries(jane)) {
console.log(`${key}: ${value}`);
}
// Output:
// first: Jane
// last: Doe
objectEntries() 的工作原理将在 专门的章节 中解释。如果没有生成器,实现相同的功能需要做更多的工作。
22.1.4 用例:更简单的异步代码
可以使用生成器极大地简化 Promise 的使用。让我们看一下基于 Promise 的函数 fetchJson() 以及如何通过生成器改进它。
function fetchJson(url) {
return fetch(url)
.then(request => request.text())
.then(text => {
return JSON.parse(text);
})
.catch(error => {
console.log(`ERROR: ${error.stack}`);
});
}
使用 co 库 和生成器,这段异步代码看起来像同步代码
const fetchJson = co.wrap(function* (url) {
try {
let request = yield fetch(url);
let text = yield request.text();
return JSON.parse(text);
}
catch (error) {
console.log(`ERROR: ${error.stack}`);
}
});
ECMAScript 2017 将具有异步函数,这些函数在内部基于生成器。使用它们,代码如下所示
async function fetchJson(url) {
try {
let request = await fetch(url);
let text = await request.text();
return JSON.parse(text);
}
catch (error) {
console.log(`ERROR: ${error.stack}`);
}
}
所有版本都可以像这样调用
fetchJson('http://example.com/some_file.json')
.then(obj => console.log(obj));
22.1.5 用例:接收异步数据
生成器可以通过 yield 接收来自 next() 的输入。这意味着每当新数据异步到达时,都可以唤醒生成器,并且对于生成器来说,感觉就像同步接收数据一样。
22.2 什么是生成器?
_生成器_ 是可以暂停和恢复的函数(想想协作式多任务处理或协程),这使得各种应用程序成为可能。
作为第一个示例,请考虑以下名为 genFunc 的生成器函数
function* genFunc() {
// (A)
console.log('First');
yield; // (B)
console.log('Second'); // (C)
}
有两件事将 genFunc 与普通函数声明区分开来
- 它以“关键字”
function*开头。 - 它可以通过
yield(B 行)暂停自身。
调用 genFunc 不会执行其主体。相反,您会得到一个所谓的 _生成器对象_,您可以使用它来控制主体的执行
genFunc() 最初在主体(A 行)之前暂停。方法调用 genObj.next() 继续执行,直到下一个 yield
正如您在最后一行中看到的,genObj.next() 也返回一个对象。现在让我们忽略这一点。它稍后会很重要。
genFunc 现在在 B 行暂停。如果我们再次调用 next(),则执行将恢复并执行 C 行
之后,函数完成,执行已离开主体,并且对 genObj.next() 的进一步调用无效。
22.2.1 生成器的作用
生成器可以扮演三种角色
- 迭代器(数据生产者):每个
yield都可以通过next()返回一个值,这意味着生成器可以通过循环和递归生成值序列。由于生成器对象实现了接口Iterable(在 关于迭代的章节 中有解释),因此这些序列可以由任何支持可迭代对象的 ECMAScript 6 结构处理。两个例子是:for-of循环和展开运算符 (...)。 - 观察者(数据消费者):
yield也可以从next()接收值(通过参数)。这意味着生成器成为数据消费者,它们会暂停,直到通过next()将新值推送到它们中。 - 协程(数据生产者和消费者):鉴于生成器是可暂停的,并且可以是数据生产者和数据消费者,因此不需要太多工作即可将它们转换为协程(协作式多任务)。
接下来的部分将更深入地解释这些角色。
22.3 作为迭代器的生成器(数据生产)
如前所述,生成器对象可以是数据生产者、数据消费者或两者兼而有之。本节将它们视为数据生产者,它们同时实现了接口 Iterable 和 Iterator(如下所示)。这意味着生成器函数的结果既是可迭代的,也是迭代器。生成器对象的完整接口将在后面显示。
interface Iterable {
[Symbol.iterator]() : Iterator;
}
interface Iterator {
next() : IteratorResult;
}
interface IteratorResult {
value : any;
done : boolean;
}
我省略了接口 Iterable 的方法 return(),因为它在本节中不相关。
生成器函数通过 yield 生成一系列值,数据消费者通过迭代器方法 next() 使用这些值。例如,以下生成器函数生成值 'a' 和 'b'
function* genFunc() {
yield 'a';
yield 'b';
}
此交互显示了如何通过生成器对象 genObj 检索生成的值
22.3.1 迭代生成器的方式
由于生成器对象是可迭代的,因此支持可迭代对象的 ES6 语言结构可以应用于它们。以下三个尤为重要。
首先,for-of 循环
for (const x of genFunc()) {
console.log(x);
}
// Output:
// a
// b
其次,展开运算符 (...),它将迭代序列转换为数组的元素(有关此运算符的更多信息,请参阅 关于参数处理的章节)
const arr = [...genFunc()]; // ['a', 'b']
第三,解构
22.3.2 从生成器返回
前面的生成器函数不包含显式的 return。隐式 return 等效于返回 undefined。让我们检查一个带有显式 return 的生成器
function* genFuncWithReturn() {
yield 'a';
yield 'b';
return 'result';
}
返回值显示在 next() 返回的最后一个对象的 done 属性为 true 中
但是,大多数使用可迭代对象的结构都会忽略 done 对象内的值
for (const x of genFuncWithReturn()) {
console.log(x);
}
// Output:
// a
// b
const arr = [...genFuncWithReturn()]; // ['a', 'b']
yield*,一个用于进行递归生成器调用的运算符,确实考虑了 done 对象内的值。稍后会解释。
22.3.3 从生成器抛出异常
如果异常离开生成器的主体,则 next() 会抛出它
function* genFunc() {
throw new Error('Problem!');
}
const genObj = genFunc();
genObj.next(); // Error: Problem!
这意味着 next() 可以产生三种不同的“结果”
- 对于迭代序列中的项
x,它返回{ value: x, done: false } - 对于返回值为
z的迭代序列的结尾,它返回{ value: z, done: true } - 对于离开生成器主体的异常,它会抛出该异常。
22.3.4 示例:迭代属性
让我们看一个示例,该示例演示了生成器对于实现可迭代对象有多方便。以下函数 objectEntries() 返回一个对象的属性的可迭代对象
function* objectEntries(obj) {
// In ES6, you can use strings or symbols as property keys,
// Reflect.ownKeys() retrieves both
const propKeys = Reflect.ownKeys(obj);
for (const propKey of propKeys) {
yield [propKey, obj[propKey]];
}
}
此函数使您可以通过 for-of 循环迭代对象 jane 的属性
const jane = { first: 'Jane', last: 'Doe' };
for (const [key,value] of objectEntries(jane)) {
console.log(`${key}: ${value}`);
}
// Output:
// first: Jane
// last: Doe
为了进行比较,不使用生成器的 objectEntries() 的实现要复杂得多
function objectEntries(obj) {
let index = 0;
let propKeys = Reflect.ownKeys(obj);
return {
[Symbol.iterator]() {
return this;
},
next() {
if (index < propKeys.length) {
let key = propKeys[index];
index++;
return { value: [key, obj[key]] };
} else {
return { done: true };
}
}
};
}
22.3.5 只能在生成器中使用 yield
生成器的一个重要限制是,只有在(静态地)位于生成器函数内部时才能 yield。也就是说,在回调中 yield 是行不通的
function* genFunc() {
['a', 'b'].forEach(x => yield x); // SyntaxError
}
在非生成器函数中不允许使用 yield,这就是为什么前面的代码会导致语法错误的原因。在这种情况下,很容易重写代码,使其不使用回调(如下所示)。但不幸的是,这并不总是可能的。
function* genFunc() {
for (const x of ['a', 'b']) {
yield x; // OK
}
}
此限制的优点在 后面解释:它使生成器更易于实现并与事件循环兼容。
22.3.6 通过 yield* 进行递归
您只能在生成器函数中使用 yield。因此,如果您想使用生成器实现递归算法,您需要一种从一个生成器调用另一个生成器的方法。本节说明这比听起来更复杂,这就是 ES6 为此提供了一个特殊运算符 yield* 的原因。现在,我只解释如果两个生成器都产生输出时 yield* 如何工作,稍后我将解释如果涉及输入时事情是如何工作的。
一个生成器如何递归地调用另一个生成器?假设您已经编写了一个生成器函数 foo
function* foo() {
yield 'a';
yield 'b';
}
您将如何从另一个生成器函数 bar 调用 foo?以下方法不起作用!
function* bar() {
yield 'x';
foo(); // does nothing!
yield 'y';
}
调用 foo() 会返回一个对象,但实际上不会执行 foo()。这就是 ECMAScript 6 使用运算符 yield* 进行递归生成器调用的原因
function* bar() {
yield 'x';
yield* foo();
yield 'y';
}
// Collect all values yielded by bar() in an array
const arr = [...bar()];
// ['x', 'a', 'b', 'y']
在内部,yield* 的工作原理大致如下
function* bar() {
yield 'x';
for (const value of foo()) {
yield value;
}
yield 'y';
}
yield* 的操作数不必是生成器对象,它可以是任何可迭代对象
function* bla() {
yield 'sequence';
yield* ['of', 'yielded'];
yield 'values';
}
const arr = [...bla()];
// ['sequence', 'of', 'yielded', 'values']
22.3.6.1 yield* 考虑迭代结束值
大多数支持可迭代对象的构造都会忽略迭代结束对象中包含的值(其属性 done 为 true)。生成器通过 return 提供该值。yield* 的结果是迭代结束值
function* genFuncWithReturn() {
yield 'a';
yield 'b';
return 'The result';
}
function* logReturned(genObj) {
const result = yield* genObj;
console.log(result); // (A)
}
如果我们想进入 A 行,我们首先必须迭代 logReturned() 生成的所有值
22.3.6.2 迭代树
使用递归迭代树很简单,而使用传统方法为树编写迭代器则很复杂。这就是生成器在这里大放异彩的原因:它们允许您通过递归实现迭代器。例如,考虑以下二叉树的数据结构。它是可迭代的,因为它有一个键为 Symbol.iterator 的方法。该方法是一个生成器方法,并在调用时返回一个迭代器。
class BinaryTree {
constructor(value, left=null, right=null) {
this.value = value;
this.left = left;
this.right = right;
}
/** Prefix iteration */
* [Symbol.iterator]() {
yield this.value;
if (this.left) {
yield* this.left;
// Short for: yield* this.left[Symbol.iterator]()
}
if (this.right) {
yield* this.right;
}
}
}
以下代码创建一个二叉树并通过 for-of 迭代它
const tree = new BinaryTree('a',
new BinaryTree('b',
new BinaryTree('c'),
new BinaryTree('d')),
new BinaryTree('e'));
for (const x of tree) {
console.log(x);
}
// Output:
// a
// b
// c
// d
// e
22.4 生成器作为观察者(数据消费)
作为数据的消费者,生成器对象符合生成器接口的后半部分,即 Observer
interface Observer {
next(value? : any) : void;
return(value? : any) : void;
throw(error) : void;
}
作为观察者,生成器会暂停,直到它接收到输入。接口指定的方法传输了三种输入
-
next()发送正常输入。 -
return()终止生成器。 -
throw()表示错误。
22.4.1 通过 next() 发送值
如果您将生成器用作观察者,则可以通过 next() 向其发送值,并通过 yield 接收这些值
function* dataConsumer() {
console.log('Started');
console.log(`1. ${yield}`); // (A)
console.log(`2. ${yield}`);
return 'result';
}
让我们以交互方式使用此生成器。首先,我们创建一个生成器对象
我们现在调用 genObj.next(),它启动生成器。执行继续,直到第一个 yield,这是生成器暂停的地方。next() 的结果是 A 行中生成的值(undefined,因为 yield 没有操作数)。在本节中,我们对 next() 返回的内容不感兴趣,因为我们只使用它来发送值,而不是检索值。
> genObj.next()
Started
{ value: undefined, done: false }
我们再调用两次 next(),以便将值 'a' 发送到第一个 yield,并将值 'b' 发送到第二个 yield
> genObj.next('a')
1. a
{ value: undefined, done: false }
> genObj.next('b')
2. b
{ value: 'result', done: true }
最后一个 next() 的结果是从 dataConsumer() 返回的值。done 为 true 表示生成器已完成。
不幸的是,next() 是不对称的,但这没办法:它总是将一个值发送到当前挂起的 yield,但返回以下 yield 的操作数。
22.4.1.1 第一个 next()
将生成器用作观察者时,请务必注意,第一次调用 next() 的唯一目的是启动观察者。它之后才准备好接收输入,因为第一次调用会将执行推进到第一个 yield。因此,您通过第一个 next() 发送的任何输入都将被忽略
function* gen() {
// (A)
while (true) {
const input = yield; // (B)
console.log(input);
}
}
const obj = gen();
obj.next('a');
obj.next('b');
// Output:
// b
最初,执行在 A 行暂停。第一次调用 next()
- 将
next()的参数'a'提供给生成器,生成器无法接收它(因为没有yield)。这就是它被忽略的原因。 - 前进到 B 行的
yield并暂停执行。 - 返回
yield的操作数(undefined,因为它没有操作数)。
第二次调用 next()
- 将
next()的参数'b'提供给生成器,生成器通过 B 行的yield接收它并将其分配给变量input。 - 然后执行继续,直到下一次循环迭代,在 B 行再次暂停。
- 然后
next()返回该yield的操作数(undefined)。
以下实用函数解决了这个问题
/**
* Returns a function that, when called,
* returns a generator object that is immediately
* ready for input via `next()`
*/
function coroutine(generatorFunction) {
return function (...args) {
const generatorObject = generatorFunction(...args);
generatorObject.next();
return generatorObject;
};
}
要查看 coroutine() 如何工作,让我们将包装的生成器与普通生成器进行比较
const wrapped = coroutine(function* () {
console.log(`First input: ${yield}`);
return 'DONE';
});
const normal = function* () {
console.log(`First input: ${yield}`);
return 'DONE';
};
包装的生成器立即准备好接收输入
普通生成器需要一个额外的 next() 才能准备好接收输入
22.4.2 yield 绑定松散
yield 绑定非常松散,因此我们不必将其操作数放在括号中
yield a + b + c;
这被视为
yield (a + b + c);
而不是
(yield a) + b + c;
因此,许多运算符的绑定比 yield 更紧密,如果您想将 yield 用作操作数,则必须将其放在括号中。例如,如果您将没有括号的 yield 作为加号的操作数,则会出现 SyntaxError
console.log('Hello' + yield); // SyntaxError
console.log('Hello' + yield 123); // SyntaxError
console.log('Hello' + (yield)); // OK
console.log('Hello' + (yield 123)); // OK
如果 yield 是函数或方法调用中的直接参数,则不需要括号
foo(yield 'a', yield 'b');
如果您在赋值的右侧使用 yield,也不需要括号
const input = yield;
22.4.2.1 ES6 语法中的 yield
ECMAScript 6 规范 中的以下语法规则可以看出 yield 周围需要括号。这些规则描述了如何解析表达式。我在这里将它们从一般(松散绑定,较低优先级)列出到特定(紧密绑定,较高优先级)。无论需要哪种表达式,您也可以使用更具体的表达式。反之则不然。层次结构以 ParenthesizedExpression 结束,这意味着如果您将任何表达式放在括号中,则可以在任何地方提及它。
AdditiveExpression 的操作数是一个 AdditiveExpression 和一个 MultiplicativeExpression。因此,使用(更具体的)ParenthesizedExpression 作为操作数是可以的,但使用(更一般的)YieldExpression 则不行。
22.4.3 return() 和 throw()
生成器对象还有两个附加方法,return() 和 throw(),它们类似于 next()。
让我们回顾一下 next(x) 如何工作(在第一次调用之后)
- 生成器当前在
yield运算符处挂起。 - 将值
x发送到该yield,这意味着它计算结果为x。 - 继续下一个
yield、return或throw-
yield x导致next()返回{ value: x, done: false } -
return x导致next()返回{ value: x, done: true } -
throw err(未在生成器内部捕获)导致next()抛出err。
-
return() 和 throw() 的工作方式类似于 next(),但它们在步骤 2 中执行不同的操作
-
return(x)在yield的位置执行return x。 -
throw(x)在yield的位置执行throw x。
22.4.4 return() 终止生成器
return() 在导致生成器最后一次挂起的 yield 的位置执行 return。让我们使用以下生成器函数来了解它是如何工作的。
function* genFunc1() {
try {
console.log('Started');
yield; // (A)
} finally {
console.log('Exiting');
}
}
在以下交互中,我们首先使用 next() 启动生成器并继续执行,直到 A 行的 yield。然后我们通过 return() 从该位置返回。
22.4.4.1 防止终止
如果您在 finally 子句中使用 yield(在该子句中使用 return 语句也是可能的),则可以防止 return() 终止生成器
function* genFunc2() {
try {
console.log('Started');
yield;
} finally {
yield 'Not done, yet!';
}
}
这一次,return() 不会退出生成器函数。因此,它返回的对象的属性 done 为 false。
您可以再调用一次 next()。与非生成器函数类似,生成器函数的返回值是在进入 finally 子句之前排队的返回值。
22.4.4.2 从新生生成器返回
允许从新生生成器(尚未启动)返回值
22.4.5 throw() 表示错误
throw() 在导致生成器最后一次挂起的 yield 的位置抛出异常。让我们通过以下生成器函数来检查它是如何工作的。
function* genFunc1() {
try {
console.log('Started');
yield; // (A)
} catch (error) {
console.log('Caught: ' + error);
}
}
在以下交互中,我们首先使用 next() 启动生成器并继续执行,直到 A 行的 yield。然后我们从该位置抛出一个异常。
> const genObj1 = genFunc1();
> genObj1.next()
Started
{ value: undefined, done: false }
> genObj1.throw(new Error('Problem!'))
Caught: Error: Problem!
{ value: undefined, done: true }
throw() 的结果(显示在最后一行)源于我们使用隐式 return 离开函数。
22.4.5.1 从新生生成器抛出
允许在新生生成器(尚未启动)中抛出异常
22.4.6 示例:处理异步推送的数据
生成器作为观察者在等待输入时会暂停,这一事实使它们非常适合按需处理异步接收的数据。设置用于处理的生成器链的模式如下
- 生成器链的每个成员(最后一个除外)都有一个参数
target。它通过yield接收数据,并通过target.next()发送数据。 - 生成器链的最后一个成员没有参数
target,只接收数据。
整个链的前缀是一个非生成器函数,它发出异步请求并通过 next() 将结果推送到生成器链中。
例如,让我们将生成器链接起来以处理异步读取的文件。
以下代码设置链:它包含生成器 splitLines、numberLines 和 printLines。数据通过非生成器函数 readFile 推送到链中。
readFile(fileName, splitLines(numberLines(printLines())));
当我展示它们的代码时,我将解释这些函数的作用。
如前所述,如果生成器通过 yield 接收输入,则对生成器对象第一次调用 next() 不会执行任何操作。这就是我在这里使用之前显示的辅助函数 coroutine() 来创建协程的原因。它为我们执行第一个 next()。
readFile() 是启动一切的非生成器函数
import {createReadStream} from 'fs';
/**
* Creates an asynchronous ReadStream for the file whose name
* is `fileName` and feeds it to the generator object `target`.
*
* @see ReadStream https://node.org.cn/api/fs.html#fs_class_fs_readstream
*/
function readFile(fileName, target) {
const readStream = createReadStream(fileName,
{ encoding: 'utf8', bufferSize: 1024 });
readStream.on('data', buffer => {
const str = buffer.toString('utf8');
target.next(str);
});
readStream.on('end', () => {
// Signal end of output sequence
target.return();
});
}
生成器链从 splitLines 开始
/**
* Turns a sequence of text chunks into a sequence of lines
* (where lines are separated by newlines)
*/
const splitLines = coroutine(function* (target) {
let previous = '';
try {
while (true) {
previous += yield;
let eolIndex;
while ((eolIndex = previous.indexOf('\n')) >= 0) {
const line = previous.slice(0, eolIndex);
target.next(line);
previous = previous.slice(eolIndex+1);
}
}
} finally {
// Handle the end of the input sequence
// (signaled via `return()`)
if (previous.length > 0) {
target.next(previous);
}
// Signal end of output sequence
target.return();
}
});
请注意一个重要的模式
-
readFile使用生成器对象方法return()来表示它发送的块序列的结束。 -
当
splitLines通过yield在无限循环中等待输入时,readFile发送该信号。return()会跳出该循环。 -
splitLines使用finally子句来处理序列结束。
下一个生成器是 numberLines
//**
* Prefixes numbers to a sequence of lines
*/
const numberLines = coroutine(function* (target) {
try {
for (const lineNo = 0; ; lineNo++) {
const line = yield;
target.next(`${lineNo}: ${line}`);
}
} finally {
// Signal end of output sequence
target.return();
}
});
最后一个生成器是 printLines
/**
* Receives a sequence of lines (without newlines)
* and logs them (adding newlines).
*/
const printLines = coroutine(function* () {
while (true) {
const line = yield;
console.log(line);
}
});
这段代码的妙处在于一切都是惰性发生的(按需):行在到达时被分割、编号和打印;我们不必等到所有文本都准备好才能开始打印。
22.4.7 yield*:完整的故事
根据经验,yield* 执行从一个生成器(调用者)到另一个生成器(被调用者)的函数调用(或等效操作)。
到目前为止,我们只看到了 yield 的一个方面:它将产生的值从被调用者传播到调用者。现在我们对接收输入的生成器感兴趣,另一个方面变得相关:yield* 还将调用者接收到的输入转发给被调用者。在某种程度上,被调用者成为活动的生成器,并且可以通过调用者的生成器对象进行控制。
22.4.7.1 示例:yield* 转发 next()
以下生成器函数 caller() 通过 yield* 调用生成器函数 callee()。
function* callee() {
console.log('callee: ' + (yield));
}
function* caller() {
while (true) {
yield* callee();
}
}
callee 记录通过 next() 接收到的值,这使我们能够检查它是否接收到我们发送到 caller 的值 'a' 和 'b'。
throw() 和 return() 以类似的方式转发。
22.4.7.2 用 JavaScript 表达的 yield* 语义
我将通过展示如何在 JavaScript 中实现它来解释 yield* 的完整语义。
以下语句
let yieldStarResult = yield* calleeFunc();
大致相当于
let yieldStarResult;
const calleeObj = calleeFunc();
let prevReceived = undefined;
while (true) {
try {
// Forward input previously received
const {value,done} = calleeObj.next(prevReceived);
if (done) {
yieldStarResult = value;
break;
}
prevReceived = yield value;
} catch (e) {
// Pretend `return` can be caught like an exception
if (e instanceof Return) {
// Forward input received via return()
calleeObj.return(e.returnedValue);
return e.returnedValue; // “re-throw”
} else {
// Forward input received via throw()
calleeObj.throw(e); // may throw
}
}
}
为了简单起见,此代码中缺少几件事
yield*的操作数可以是任何可迭代的值。-
return()和throw()是可选的迭代器方法。我们应该只在它们存在时才调用它们。 - 如果收到异常并且
throw()不存在,但return()存在,则调用return()(在抛出异常之前)以使calleeObject有机会清理。 -
calleeObj可以通过返回一个属性done为false的对象来拒绝关闭。然后调用者也必须拒绝关闭,并且yield*必须继续迭代。
22.5 作为协程的生成器(协作式多任务处理)
我们已经看到生成器被用作数据的源或接收器。对于许多应用程序来说,严格区分这两个角色是一个好习惯,因为它可以使事情变得更简单。本节描述完整的生成器接口(它结合了这两个角色)以及需要这两个角色的一个用例:协作式多任务处理,其中任务必须能够发送和接收信息。
22.5.1 完整的生成器接口
生成器对象 Generator 的完整接口处理输出和输入
interface Generator {
next(value? : any) : IteratorResult;
throw(value? : any) : IteratorResult;
return(value? : any) : IteratorResult;
}
interface IteratorResult {
value : any;
done : boolean;
}
接口 Generator 结合了我们之前看到的两个接口:用于输出的 Iterator 和用于输入的 Observer。
interface Iterator { // data producer
next() : IteratorResult;
return?(value? : any) : IteratorResult;
}
interface Observer { // data consumer
next(value? : any) : void;
return(value? : any) : void;
throw(error) : void;
}
22.5.2 协作式多任务处理
协作式多任务处理是生成器的一种应用,我们需要它们来处理输出和输入。在我们了解它是如何工作之前,让我们先回顾一下 JavaScript 中并行性的现状。
JavaScript 在单个进程中运行。目前有两种方法可以打破这种限制
- 多进程:Web Workers 允许您在多个进程中运行 JavaScript。共享数据访问是多进程处理的最大缺陷之一。Web Workers 通过不共享任何数据来避免这种情况。也就是说,如果您希望 Web Worker 拥有一段数据,您必须向其发送一份副本或将您的数据传输给它(之后您将无法再访问它)。
- 协作式多任务处理:有各种模式和库在尝试协作式多任务处理。运行多个任务,但一次只运行一个。每个任务都必须明确地暂停自身,从而完全控制何时发生任务切换。在这些实验中,数据通常在任务之间共享。但由于明确的暂停,风险很小。
有两个用例受益于协作式多任务处理,因为它们涉及的控制流无论如何都主要是顺序的,偶尔会有暂停
- 流:任务顺序处理数据流,并在没有可用数据时暂停。
-
异步计算:任务阻塞(暂停),直到它收到长时间运行的计算结果。
- 在 JavaScript 中,Promise 已成为处理异步计算的流行方式。对它们的支 持包含在 ES6 中。下一节解释了生成器如何简化 Promise 的使用。
22.5.2.1 通过生成器简化异步计算
几个基于 Promise 的库通过生成器简化了异步代码。生成器非常适合作为 Promise 的客户端,因为它们可以暂停直到结果到达。
以下示例演示了如果使用 T.J. Holowaychuk 的库 co 会是什么样子。我们需要两个库(如果我们通过 babel-node 运行 Node.js 代码)
import fetch from 'isomorphic-fetch';
const co = require('co');
co 是用于协作式多任务处理的实际库,isomorphic-fetch 是新的基于 Promise 的 fetch API(XMLHttpRequest 的替代品;阅读 Jake Archibald 的“That’s so fetch!”了解更多信息)的 polyfill。 fetch 可以轻松编写一个函数 getFile,该函数通过 Promise 返回 url 处的文件文本
function getFile(url) {
return fetch(url)
.then(request => request.text());
}
现在我们有了使用 co 的所有要素。以下任务读取两个文件的文本,解析其中的 JSON 并记录结果。
co(function* () {
try {
const [croftStr, bondStr] = yield Promise.all([ // (A)
getFile('https://:8000/croft.json'),
getFile('https://:8000/bond.json'),
]);
const croftJson = JSON.parse(croftStr);
const bondJson = JSON.parse(bondStr);
console.log(croftJson);
console.log(bondJson);
} catch (e) {
console.log('Failure to read: ' + e);
}
});
请注意这段代码看起来多么同步,即使它在 A 行中进行了异步调用。作为任务的生成器通过向调度器函数 co 生成 Promise 来进行异步调用。生成会暂停生成器。一旦 Promise 返回结果,调度器就会通过 next() 将结果传递给生成器来恢复生成器。 co 的简化版本如下所示。
function co(genFunc) {
const genObj = genFunc();
step(genObj.next());
function step({value,done}) {
if (!done) {
// A Promise was yielded
value
.then(result => {
step(genObj.next(result)); // (A)
})
.catch(error => {
step(genObj.throw(error)); // (B)
});
}
}
}
我忽略了 next()(A 行)和 throw()(B 行)可能会抛出异常(每当异常从生成器函数体中逃逸时)。
22.5.3 通过生成器进行协作式多任务处理的局限性
协程是协作式多任务处理的任务,它们没有限制:在协程内部,任何函数都可以暂停整个协程(函数激活本身、函数调用者的激活、调用者的调用者,等等)。
相反,您只能从生成器内部直接暂停生成器,并且只暂停当前的函数激活。由于这些限制,生成器有时被称为浅层协程 [3]。
22.5.3.1 生成器限制的好处
生成器的限制有两个主要好处
- 生成器与事件循环兼容,后者在浏览器中提供简单的协作式多任务处理。我稍后会解释细节。
- 生成器相对容易实现,因为只需要暂停单个函数激活,并且因为浏览器可以继续使用事件循环。
JavaScript 已经有一种非常简单的协作式多任务处理风格:事件循环,它在队列中调度任务的执行。每个任务都通过调用函数来启动,并在该函数完成后完成。事件、setTimeout() 和其他机制将任务添加到队列中。
这种多任务处理风格做出了一个重要的保证:运行完成;每个函数都可以依赖于在完成之前不会被另一个任务中断。函数成为事务,并且可以执行完整的算法,而无需任何人看到它们在中间状态下操作的数据。对共享数据的并发访问使多任务处理变得复杂,并且 JavaScript 的并发模型不允许这样做。这就是为什么运行完成是一件好事。
唉,协程阻止了运行完成,因为任何函数都可以暂停其调用者。例如,以下算法由多个步骤组成
如果 step2 要暂停算法,则其他任务可以在执行算法的最后一步之前运行。这些任务可能包含应用程序的其他部分,这些部分会看到 sharedData 处于未完成状态。生成器保留运行完成,它们只暂停自身并返回到它们的调用者。
co 和类似的库为您提供了协程的大部分功能,而没有它们的缺点
- 它们为通过生成器定义的任务提供调度程序。
- 任务“是”生成器,因此可以完全暂停。
- 递归(生成器)函数调用只有在通过
yield*完成时才能暂停。这使调用者可以控制暂停。
22.6 生成器示例
本节给出了一些生成器用途的示例。
22.6.1 通过生成器实现可迭代对象
在关于迭代的章节中,我“手动”实现了几个可迭代对象。在本节中,我改用生成器。
22.6.1.1 可迭代组合器 take()
take() 将(可能是无限的)迭代值序列转换为长度为 n 的序列
function* take(n, iterable) {
for (const x of iterable) {
if (n <= 0) return;
n--;
yield x;
}
}
以下是使用它的示例
const arr = ['a', 'b', 'c', 'd'];
for (const x of take(2, arr)) {
console.log(x);
}
// Output:
// a
// b
没有生成器的 take() 的实现更复杂
function take(n, iterable) {
const iter = iterable[Symbol.iterator]();
return {
[Symbol.iterator]() {
return this;
},
next() {
if (n > 0) {
n--;
return iter.next();
} else {
maybeCloseIterator(iter);
return { done: true };
}
},
return() {
n = 0;
maybeCloseIterator(iter);
}
};
}
function maybeCloseIterator(iterator) {
if (typeof iterator.return === 'function') {
iterator.return();
}
}
请注意,可迭代组合器 zip() 没有从通过生成器实现中获益太多,因为涉及多个可迭代对象并且不能使用 for-of。
22.6.1.2 无限迭代器
naturalNumbers() 返回一个对所有自然数的可迭代对象
function* naturalNumbers() {
for (let n=0;; n++) {
yield n;
}
}
此函数通常与组合器一起使用
for (const x of take(3, naturalNumbers())) {
console.log(x);
}
// Output
// 0
// 1
// 2
这是非生成器实现,因此您可以进行比较
function naturalNumbers() {
let n = 0;
return {
[Symbol.iterator]() {
return this;
},
next() {
return { value: n++ };
}
}
}
22.6.1.3 受数组启发的可迭代组合器:map、filter
可以使用 map 和 filter 方法转换数组。这些方法可以概括为将可迭代对象作为输入并将可迭代对象作为输出。
22.6.1.3.1 广义 map()
这是 map 的广义版本
function* map(iterable, mapFunc) {
for (const x of iterable) {
yield mapFunc(x);
}
}
map() 适用于无限迭代器
22.6.1.3.2 广义 filter()
这是 filter 的广义版本
function* filter(iterable, filterFunc) {
for (const x of iterable) {
if (filterFunc(x)) {
yield x;
}
}
}
filter() 适用于无限迭代器
22.6.2 用于惰性求值的生成器
接下来的两个例子展示了如何使用生成器来处理字符流。
- 输入是一个字符流。
- 步骤 1 – 词法分析(字符 → 单词):字符被分组为*单词*,即匹配正则表达式
/^[A-Za-z0-9]+$/的字符串。非单词字符将被忽略,但它们会分隔单词。此步骤的输入是字符流,输出是单词流。 - 步骤 2 – 提取数字(单词 → 数字):仅保留匹配正则表达式
/^[0-9]+$/的单词,并将它们转换为数字。 - 步骤 3 – 添加数字(数字 → 数字):对于接收到的每个数字,返回到目前为止接收到的总数。
妙处在于,所有内容都是*惰性*计算的(增量式和按需):计算在第一个字符到达时立即开始。例如,我们不必等到拥有所有字符才能获得第一个单词。
22.6.2.1 惰性拉取(生成器作为迭代器)
使用生成器的惰性拉取工作原理如下。实现步骤 1-3 的三个生成器按如下方式链接
addNumbers(extractNumbers(tokenize(CHARS)))
每个链成员都从源拉取数据并生成一系列项目。处理从 tokenize 开始,其源是字符串 CHARS。
22.6.2.1.1 步骤 1 – 词法分析
以下技巧使代码更简单一些:序列结束迭代器结果(其属性 done 为 false)将转换为哨兵值 END_OF_SEQUENCE。
/**
* Returns an iterable that transforms the input sequence
* of characters into an output sequence of words.
*/
function* tokenize(chars) {
const iterator = chars[Symbol.iterator]();
let ch;
do {
ch = getNextItem(iterator); // (A)
if (isWordChar(ch)) {
let word = '';
do {
word += ch;
ch = getNextItem(iterator); // (B)
} while (isWordChar(ch));
yield word; // (C)
}
// Ignore all other characters
} while (ch !== END_OF_SEQUENCE);
}
const END_OF_SEQUENCE = Symbol();
function getNextItem(iterator) {
const {value,done} = iterator.next();
return done ? END_OF_SEQUENCE : value;
}
function isWordChar(ch) {
return typeof ch === 'string' && /^[A-Za-z0-9]$/.test(ch);
}
这个生成器是如何实现惰性的?当您通过 next() 向它请求一个标记时,它会根据需要多次拉取其 iterator(A 行和 B 行)以生成一个标记,然后生成该标记(C 行)。然后它会暂停,直到再次被请求提供标记。这意味着只要第一个字符可用,词法分析就会开始,这对于流来说很方便。
让我们尝试一下词法分析。请注意,空格和点是非单词。它们被忽略,但它们分隔单词。我们利用了字符串是字符(Unicode 代码点)的可迭代对象这一事实。tokenize() 的结果是一个单词的可迭代对象,我们通过扩展运算符 (...) 将其转换为数组。
22.6.2.1.2 步骤 2 – 提取数字
这一步相对简单,我们只 yield 只包含数字的单词,并在通过 Number() 将其转换为数字之后。
/**
* Returns an iterable that filters the input sequence
* of words and only yields those that are numbers.
*/
function* extractNumbers(words) {
for (const word of words) {
if (/^[0-9]+$/.test(word)) {
yield Number(word);
}
}
}
您再次可以看到惰性:如果您通过 next() 请求一个数字,一旦在 words 中遇到一个数字,您就会得到一个数字(通过 yield)。
让我们从单词数组中提取数字
请注意,字符串已转换为数字。
22.6.2.1.3 步骤 3 – 添加数字
/**
* Returns an iterable that contains, for each number in
* `numbers`, the total sum of numbers encountered so far.
* For example: 7, 4, -1 --> 7, 11, 10
*/
function* addNumbers(numbers) {
let result = 0;
for (const n of numbers) {
result += n;
yield result;
}
}
让我们尝试一个简单的例子
> [...addNumbers([5, -2, 12])]
[ 5, 3, 15 ]
22.6.2.1.4 拉取输出
生成器链本身不会产生输出。我们需要通过扩展运算符主动拉取输出
const CHARS = '2 apples and 5 oranges.';
const CHAIN = addNumbers(extractNumbers(tokenize(CHARS)));
console.log([...CHAIN]);
// [ 2, 7 ]
辅助函数 logAndYield 允许我们检查事物是否确实是惰性计算的
function* logAndYield(iterable, prefix='') {
for (const item of iterable) {
console.log(prefix + item);
yield item;
}
}
const CHAIN2 = logAndYield(addNumbers(extractNumbers(tokenize(logAndYield(CHA\
RS)))), '-> ');
[...CHAIN2];
// Output:
// 2
//
// -> 2
// a
// p
// p
// l
// e
// s
//
// a
// n
// d
//
// 5
//
// -> 7
// o
// r
// a
// n
// g
// e
// s
// .
输出显示,一旦接收到字符 '2' 和 ' ',addNumbers 就会产生结果。
22.6.2.2 惰性推送(生成器作为可观察对象)
将之前的基于拉取的算法转换为基于推送的算法不需要太多工作。步骤相同。但我们不是通过拉取来完成,而是通过推送来开始。
如前所述,如果生成器通过 yield 接收输入,则对生成器对象第一次调用 next() 不会执行任何操作。这就是我在这里使用之前显示的辅助函数 coroutine() 来创建协程的原因。它为我们执行第一个 next()。
以下函数 send() 执行推送。
/**
* Pushes the items of `iterable` into `sink`, a generator.
* It uses the generator method `next()` to do so.
*/
function send(iterable, sink) {
for (const x of iterable) {
sink.next(x);
}
sink.return(); // signal end of stream
}
当生成器处理流时,它需要知道流的结束,以便它可以正确清理。对于拉取,我们通过特殊的流结束哨兵来做到这一点。对于推送,流结束是通过 return() 来指示的。
让我们通过一个简单地输出它接收到的所有内容的生成器来测试 send()
/**
* This generator logs everything that it receives via `next()`.
*/
const logItems = coroutine(function* () {
try {
while (true) {
const item = yield; // receive item via `next()`
console.log(item);
}
} finally {
console.log('DONE');
}
});
让我们通过字符串(它是 Unicode 代码点的可迭代对象)向 logItems() 发送三个字符。
22.6.2.2.1 步骤 1 – 词法分析
请注意,此生成器如何在两个 finally 子句中对流的结束(通过 return() 指示)做出反应。我们依赖于将 return() 发送到两个 yield 中的任何一个。否则,生成器将永远不会终止,因为从 A 行开始的无限循环将永远不会终止。
/**
* Receives a sequence of characters (via the generator object
* method `next()`), groups them into words and pushes them
* into the generator `sink`.
*/
const tokenize = coroutine(function* (sink) {
try {
while (true) { // (A)
let ch = yield; // (B)
if (isWordChar(ch)) {
// A word has started
let word = '';
try {
do {
word += ch;
ch = yield; // (C)
} while (isWordChar(ch));
} finally {
// The word is finished.
// We get here if
// - the loop terminates normally
// - the loop is terminated via `return()` in line C
sink.next(word); // (D)
}
}
// Ignore all other characters
}
} finally {
// We only get here if the infinite loop is terminated
// via `return()` (in line B or C).
// Forward `return()` to `sink` so that it is also
// aware of the end of stream.
sink.return();
}
});
function isWordChar(ch) {
return /^[A-Za-z0-9]$/.test(ch);
}
这一次,惰性是由推送驱动的:一旦生成器接收到足够多的字符来组成一个单词(在 C 行中),它就会将该单词推送到 sink 中(D 行)。也就是说,生成器不会等到它接收到所有字符。
tokenize() 演示了生成器可以很好地作为线性状态机的实现。在这种情况下,机器有两种状态:“在单词内”和“不在单词内”。
让我们对字符串进行词法分析
22.6.2.2.2 步骤 2 – 提取数字
这一步很简单。
/**
* Receives a sequence of strings (via the generator object
* method `next()`) and pushes only those strings to the generator
* `sink` that are “numbers” (consist only of decimal digits).
*/
const extractNumbers = coroutine(function* (sink) {
try {
while (true) {
const word = yield;
if (/^[0-9]+$/.test(word)) {
sink.next(Number(word));
}
}
} finally {
// Only reached via `return()`, forward.
sink.return();
}
});
事情又是惰性的:一旦遇到一个数字,它就会被推送到 sink。
让我们从单词数组中提取数字
请注意,输入是一个字符串序列,而输出是一个数字序列。
22.6.2.2.3 步骤 3 – 添加数字
这一次,我们通过推送单个值然后关闭接收器来对流的结束做出反应。
/**
* Receives a sequence of numbers (via the generator object
* method `next()`). For each number, it pushes the total sum
* so far to the generator `sink`.
*/
const addNumbers = coroutine(function* (sink) {
let sum = 0;
try {
while (true) {
sum += yield;
sink.next(sum);
}
} finally {
// We received an end-of-stream
sink.return(); // signal end of stream
}
});
让我们试试这个生成器
22.6.2.2.4 推送输入
生成器链从 tokenize 开始,到 logItems 结束,后者记录它接收到的所有内容。我们通过 send 将一系列字符推送到链中
const INPUT = '2 apples and 5 oranges.';
const CHAIN = tokenize(extractNumbers(addNumbers(logItems())));
send(INPUT, CHAIN);
// Output
// 2
// 7
// DONE
以下代码证明了处理确实是惰性发生的
const CHAIN2 = tokenize(extractNumbers(addNumbers(logItems({ prefix: '-> ' })\
)));
send(INPUT, CHAIN2, { log: true });
// Output
// 2
//
// -> 2
// a
// p
// p
// l
// e
// s
//
// a
// n
// d
//
// 5
//
// -> 7
// o
// r
// a
// n
// g
// e
// s
// .
// DONE
输出显示,一旦推送字符 '2' 和 ' ',addNumbers 就会产生结果。
22.6.3 通过生成器进行协作式多任务处理
22.6.3.1 暂停长时间运行的任务
在本例中,我们将创建一个显示在网页上的计数器。我们改进了初始版本,直到我们拥有一个不会阻塞主线程和用户界面的协作式多任务版本。
这是网页中应该显示计数器的部分
<body>
Counter: <span id="counter"></span>
</body>
此函数显示一个永远递增的计数器5
function countUp(start = 0) {
const counterSpan = document.querySelector('#counter');
while (true) {
counterSpan.textContent = String(start);
start++;
}
}
如果您运行此函数,它将完全阻塞运行它的用户界面线程,并且其选项卡将变得无响应。
让我们通过一个生成器来实现相同的功能,该生成器通过 yield 定期暂停(稍后将显示运行此生成器的调度函数)
function* countUp(start = 0) {
const counterSpan = document.querySelector('#counter');
while (true) {
counterSpan.textContent = String(start);
start++;
yield; // pause
}
}
让我们添加一个小改进。我们将用户界面的更新移动到另一个生成器 displayCounter,我们通过 yield* 调用它。因为它是一个生成器,所以它也可以处理暂停。
function* countUp(start = 0) {
while (true) {
start++;
yield* displayCounter(start);
}
}
function* displayCounter(counter) {
const counterSpan = document.querySelector('#counter');
counterSpan.textContent = String(counter);
yield; // pause
}
最后,这是一个调度函数,我们可以使用它来运行 countUp()。生成器的每个执行步骤都由一个单独的任务处理,该任务是通过 setTimeout() 创建的。这意味着用户界面可以在两者之间安排其他任务,并且将保持响应。
function run(generatorObject) {
if (!generatorObject.next().done) {
// Add a new task to the event queue
setTimeout(function () {
run(generatorObject);
}, 1000);
}
}
在 run 的帮助下,我们得到了一个(几乎)无限的计数,它不会阻塞用户界面
run(countUp());
22.6.3.2 使用生成器和 Node.js 风格的回调进行协作式多任务处理
如果您调用生成器函数(或方法),它将无法访问其生成器对象;它的 this 将是它作为非生成器函数时的 this。一种解决方法是通过 yield 将生成器对象传递给生成器函数。
以下 Node.js 脚本使用了这种技术,但将生成器对象包装在回调(next,A 行)中。它必须通过 babel-node 运行。
import {readFile} from 'fs';
const fileNames = process.argv.slice(2);
run(function* () {
const next = yield;
for (const f of fileNames) {
const contents = yield readFile(f, { encoding: 'utf8' }, next);
console.log('##### ' + f);
console.log(contents);
}
});
在 A 行中,我们获得了一个回调,我们可以将其与遵循 Node.js 回调约定的函数一起使用。回调使用生成器对象来唤醒生成器,如您在 run() 的实现中所见
function run(generatorFunction) {
const generatorObject = generatorFunction();
// Step 1: Proceed to first `yield`
generatorObject.next();
// Step 2: Pass in a function that the generator can use as a callback
function nextFunction(error, result) {
if (error) {
generatorObject.throw(error);
} else {
generatorObject.next(result);
}
}
generatorObject.next(nextFunction);
// Subsequent invocations of `next()` are triggered by `nextFunction`
}
22.6.3.3 通信顺序进程 (CSP)
库 js-csp 将通信顺序进程 (CSP) 引入 JavaScript,这是一种协作式多任务处理风格,类似于 ClojureScript 的 core.async 和 Go 的*goroutines*。js-csp 有两个抽象
- 进程:是协作式多任务处理任务,通过将生成器函数传递给调度函数
go()来实现。 - 通道:是进程之间通信的队列。通道是通过调用
chan()创建的。
例如,让我们使用 CSP 来处理 DOM 事件,其方式类似于函数式响应式编程。以下代码使用函数 listen()(稍后显示)来创建一个输出 mousemove 事件的通道。然后,它在一个无限循环中通过 take 连续检索输出。多亏了 yield,该进程会阻塞,直到通道有输出。
import csp from 'js-csp';
csp.go(function* () {
const element = document.querySelector('#uiElement1');
const channel = listen(element, 'mousemove');
while (true) {
const event = yield csp.take(channel);
const x = event.layerX || event.clientX;
const y = event.layerY || event.clientY;
element.textContent = `${x}, ${y}`;
}
});
listen() 的实现如下。
function listen(element, type) {
const channel = csp.chan();
element.addEventListener(type,
event => {
csp.putAsync(channel, event);
});
return channel;
}
22.7 迭代 API(包括生成器)中的继承
这是 ECMAScript 6 中各种对象如何连接的图表(它基于 ECMAScript 规范中Allen Wirf-Brock 的图表)
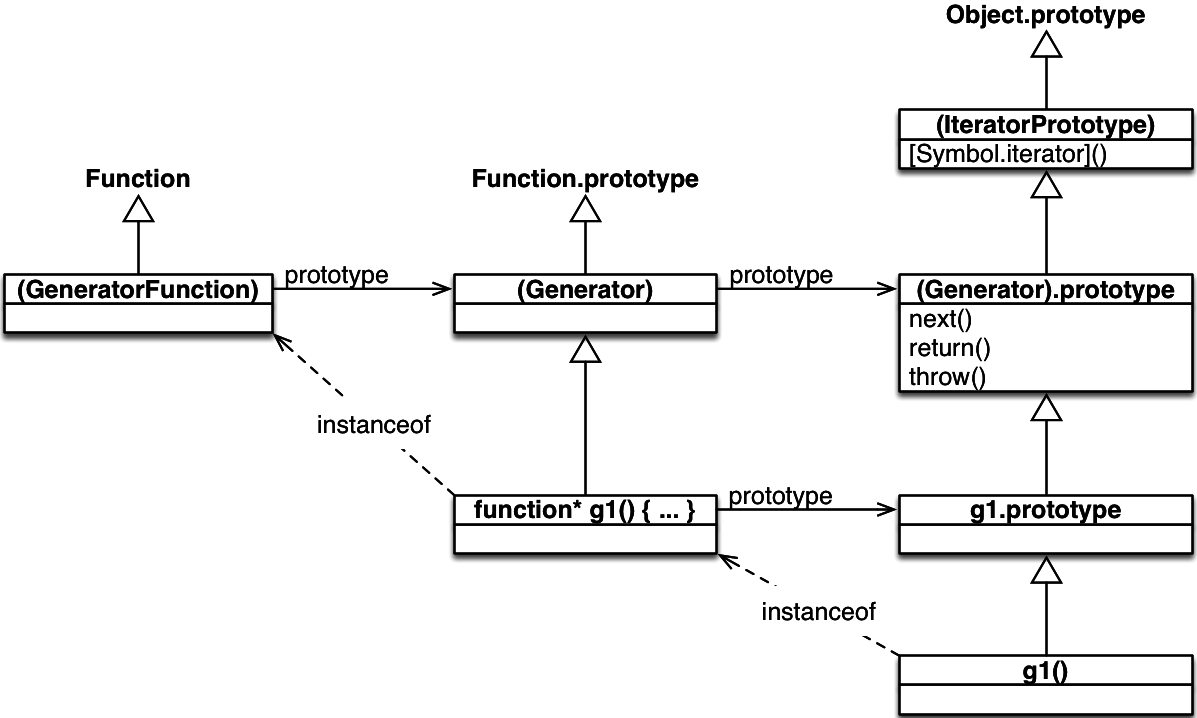
图例
- 白色(空心)箭头表示对象之间的 has-prototype 关系(继承)。换句话说:从
x到y的白色箭头表示Object.getPrototypeOf(x) === y。 - 括号表示对象存在,但无法通过全局变量访问。
- 从
x到y的instanceof箭头表示x instanceof y。- 请记住,
o instanceof C等效于C.prototype.isPrototypeOf(o)。
- 请记住,
- 从
x到y的prototype箭头表示x.prototype === y。 - 右列显示了一个实例及其原型,中间列显示了一个函数及其原型,左列显示了函数的类(如果您愿意,可以称之为元函数),它们通过子类关系连接在一起。
该图揭示了两个有趣的事实
首先,生成器函数 g 的工作方式与构造函数非常相似(但是,您不能通过 new 来调用它;这会导致 TypeError):它创建的生成器对象是它的实例,添加到 g.prototype 的方法成为原型方法,等等。
> function* g() {}
> g.prototype.hello = function () { return 'hi!'};
> const obj = g();
> obj instanceof g
true
> obj.hello()
'hi!'
其次,如果您想为所有生成器对象提供方法,最好将它们添加到 (Generator).prototype。访问该对象的一种方法如下
const Generator = Object.getPrototypeOf(function* () {});
Generator.prototype.hello = function () { return 'hi!'};
const generatorObject = (function* () {})();
generatorObject.hello(); // 'hi!'
22.7.1 IteratorPrototype
图中没有 (Iterator),因为不存在这样的对象。但是,考虑到 instanceof 的工作原理以及 (IteratorPrototype) 是 g1() 的原型,您仍然可以说 g1() 是 Iterator 的实例。
ES6 中的所有迭代器在其原型链中都有 (IteratorPrototype)。该对象是可迭代的,因为它具有以下方法。因此,所有 ES6 迭代器都是可迭代的(因此,您可以对它们应用 for-of 等)。
[Symbol.iterator]() {
return this;
}
规范建议使用以下代码来访问 (IteratorPrototype)
const proto = Object.getPrototypeOf.bind(Object);
const IteratorPrototype = proto(proto([][Symbol.iterator]()));
你也可以使用
const IteratorPrototype = proto(proto(function* () {}.prototype));
引用 ECMAScript 6 规范
ECMAScript 代码也可以定义从
IteratorPrototype继承的对象。IteratorPrototype对象提供了一个地方,可以添加适用于所有迭代器对象的附加方法。
IteratorPrototype 可能会在即将发布的 ECMAScript 版本中直接访问,并包含诸如 map() 和 filter() 之类的工具方法(来源)。
22.7.2 生成器中 this 的值
生成器函数结合了两个方面
- 它是一个设置并返回生成器对象的函数。
- 它包含生成器对象逐步执行的代码。
这就是为什么在生成器内部 this 的值不那么明显的原因。
在函数调用和方法调用中,this 的值与 gen() 不是生成器函数而是普通函数时的值相同
function* gen() {
'use strict'; // just in case
yield this;
}
// Retrieve the yielded value via destructuring
const [functionThis] = gen();
console.log(functionThis); // undefined
const obj = { method: gen };
const [methodThis] = obj.method();
console.log(methodThis === obj); // true
如果在通过 new 调用的生成器中访问 this,则会收到 ReferenceError(来源:ES6 规范)
function* gen() {
console.log(this); // ReferenceError
}
new gen();
一种解决方法是将生成器包装在一个普通函数中,该函数通过 next() 将其生成器对象传递给生成器。这意味着生成器必须使用其第一个 yield 来检索其生成器对象
const generatorObject = yield;
22.8 样式考虑:星号前后空格
格式化星号的合理且合法的变体是
- 前后各有一个空格
function * foo(x, y) { ··· } - 前面有一个空格
function *foo(x, y) { ··· } - 后面有一个空格
function* foo(x, y) { ··· } - 前后没有空格
function*foo(x, y) { ··· }
让我们弄清楚哪些变体对哪些结构有意义以及为什么。
22.8.1 生成器函数声明和表达式
在这里,只使用星号是因为 generator(或类似的东西)不能用作关键字。如果是这样,则生成器函数声明将如下所示
generator foo(x, y) {
···
}
ECMAScript 6 没有使用 generator,而是在 function 关键字上标记了一个星号。因此,function* 可以看作是 generator 的同义词,这表明生成器函数声明的写法如下。
function* foo(x, y) {
···
}
匿名生成器函数表达式的格式如下
const foo = function* (x, y) {
···
}
22.8.2 生成器方法定义
在编写生成器方法定义时,我建议按如下方式格式化星号。
const obj = {
* generatorMethod(x, y) {
···
}
};
有三个理由支持在星号后写一个空格。
首先,星号不应该是方法名称的一部分。一方面,它不是生成器函数名称的一部分。另一方面,星号仅在定义生成器时提及,而在使用生成器时不提及。
其次,生成器方法定义是以下语法的缩写。(为了说明我的观点,我还冗余地为函数表达式指定了名称。)
const obj = {
generatorMethod: function* generatorMethod(x, y) {
···
}
};
如果方法定义是关于省略 function 关键字,则星号后面应该跟一个空格。
第三,生成器方法定义在语法上类似于 getter 和 setter(在 ECMAScript 5 中已经可用)
const obj = {
get foo() {
···
}
set foo(value) {
···
}
};
关键字 get 和 set 可以看作是普通方法定义的修饰符。可以说,星号也是这样的修饰符。
22.8.3 格式化递归 yield
以下是递归地生成其自身生成值的生成器函数的示例
function* foo(x) {
···
yield* foo(x - 1);
···
}
星号标记了一种不同类型的 yield 运算符,这就是为什么上述写法有意义的原因。
22.8.4 记录生成器函数和方法
Kyle Simpson(@getify)提出了一个有趣的想法:鉴于我们经常在编写函数和方法(如 Math.max())时附加括号,那么在编写生成器函数和方法时添加星号是否有意义?例如:我们是否应该写成 *foo() 来指代上一小节中的生成器函数?让我来反驳一下。
在编写返回可迭代对象的函数时,生成器只是几种选择之一。我认为最好不要通过标记函数名称来泄露此实现细节。
此外,在调用生成器函数时不使用星号,但会使用括号。
最后,星号没有提供有用的信息——yield* 也可以与返回可迭代对象的函数一起使用。但是,标记返回可迭代对象的函数和方法(包括生成器)的名称可能是有意义的。例如,通过后缀 Iter。
22.9 常见问题解答:生成器
22.9.1 为什么对生成器使用关键字 function* 而不是 generator?
由于向后兼容性,使用关键字 generator 不是一个选项。例如,以下代码(一个假设的 ES6 匿名生成器表达式)可以是一个 ES5 函数调用,后面跟着一个代码块。
generator (a, b, c) {
···
}
我发现星号命名方案可以很好地扩展到 yield*。
22.9.2 yield 是关键字吗?
yield 仅在严格模式下是保留字。ES6 宽松模式下使用了一个技巧来引入它:它变成了一个*上下文关键字*,一个只能在生成器内部使用的关键字。
22.10 结论
我希望本章能让您相信生成器是一个有用且通用的工具。
我喜欢生成器可以让您实现协作式多任务,这些任务在进行异步函数调用时会阻塞。在我看来,这是异步调用的正确心智模型。希望 JavaScript 在未来能朝着这个方向进一步发展。
22.11 延伸阅读
本章来源
[1] Jafar Husain 的“异步生成器提案”
[2] David Beazley 的“协程和并发奇异之旅”
[3] David Herman 的“为什么协程在 Web 上不起作用”