24. 异步编程(背景)
本章解释了 JavaScript 中异步编程的基础知识。它为 下一章关于 ES6 Promises 的内容 提供了背景知识。
- 24.1. JavaScript 调用栈
- 24.2. 浏览器事件循环
- 24.2.1. 定时器
- 24.2.2. 显示 DOM 更改
- 24.2.3. 运行至完成语义
- 24.2.4. 阻塞事件循环
- 24.2.5. 避免阻塞
- 24.3. 异步接收结果
- 24.3.1. 通过事件异步获取结果
- 24.3.2. 通过回调函数异步获取结果
- 24.3.3. 延续传递风格
- 24.3.4. 在 CPS 中组合代码
- 24.3.5. 回调函数的优缺点
- 24.4. 展望
- 24.5. 扩展阅读
24.1 JavaScript 调用栈
当函数 f 调用函数 g 时,g 需要知道在它完成后返回到哪里(在 f 内部)。此信息通常由一个栈来管理,即*调用栈*。让我们看一个例子。
function h(z) {
// Print stack trace
console.log(new Error().stack); // (A)
}
function g(y) {
h(y + 1); // (B)
}
function f(x) {
g(x + 1); // (C)
}
f(3); // (D)
return; // (E)
最初,当程序启动时,调用栈是空的。在第 D 行调用函数 f(3) 后,栈中有一个条目
- 全局作用域中的位置
在第 C 行调用函数 g(x + 1) 后,栈中有两个条目
f中的位置- 全局作用域中的位置
在第 B 行调用函数 h(y + 1) 后,栈中有三个条目
g中的位置f中的位置- 全局作用域中的位置
第 A 行打印的堆栈跟踪显示了调用栈的外观
接下来,每个函数都终止,并且每次都从栈中删除顶部条目。函数 f 完成后,我们回到全局作用域,调用栈为空。在第 E 行,我们返回并且栈为空,这意味着程序终止。
24.2 浏览器事件循环
简单来说,每个浏览器选项卡都在一个单独的进程中运行:事件循环。此循环执行通过*任务队列* 提供给它的浏览器相关内容(所谓的*任务*)。任务的例子有
- 解析 HTML
- 在 script 元素中执行 JavaScript 代码
- 响应用户输入(鼠标点击、按键等)
- 处理异步网络请求的结果
项目 2-4 是通过内置于浏览器的引擎运行 JavaScript 代码的任务。它们在代码终止时终止。然后可以执行队列中的下一个任务。下图(灵感来自 Philip Roberts 的幻灯片 [1])概述了所有这些机制是如何连接的。
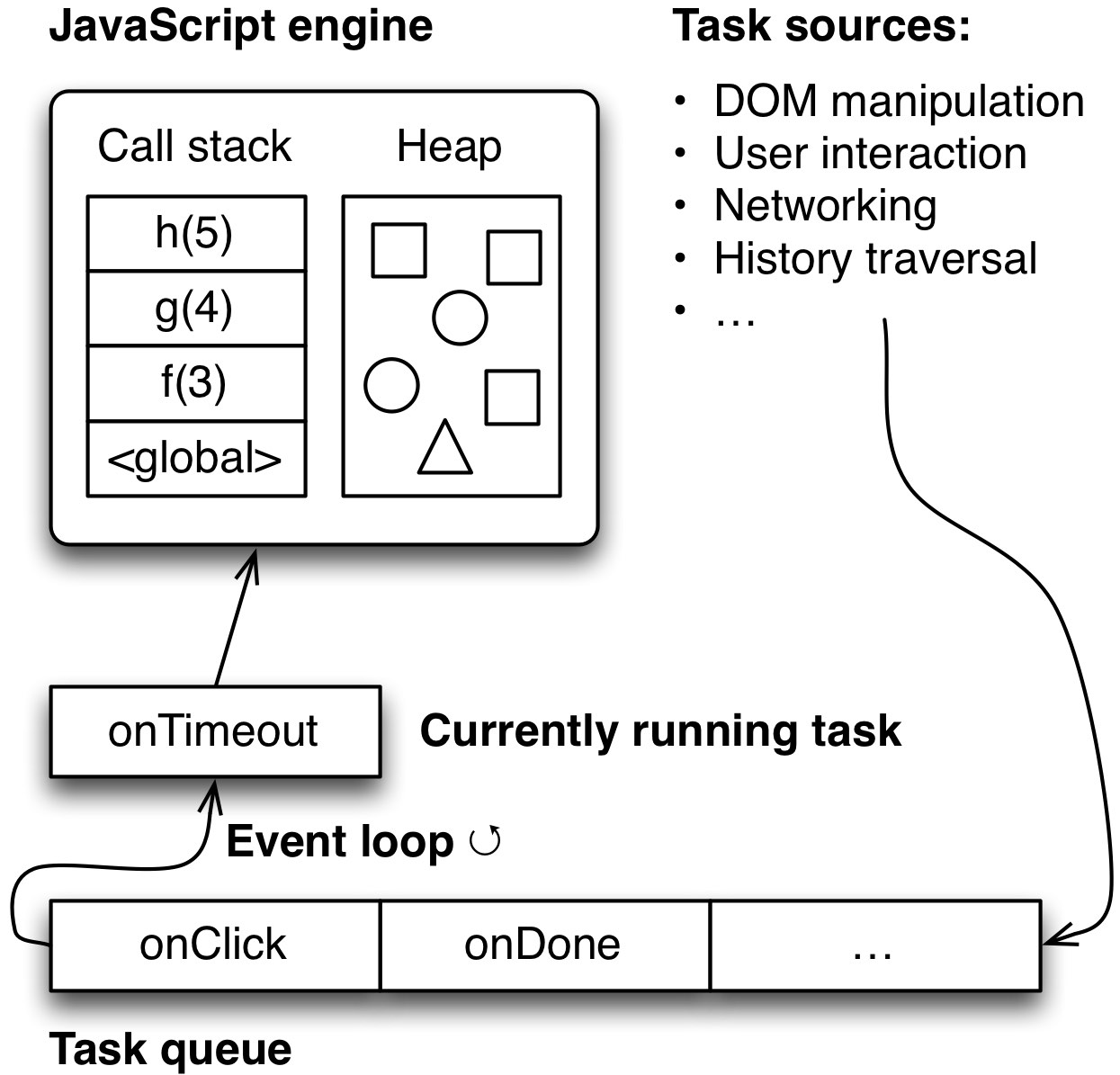
事件循环被其他与其并行运行的进程(定时器、输入处理等)包围。这些进程通过向其队列添加任务来与其通信。
24.2.1 定时器
浏览器有 定时器。setTimeout() 创建一个定时器,等待它触发,然后向队列添加一个任务。它具有以下签名
setTimeout(callback, ms)
在 ms 毫秒后,callback 被添加到任务队列中。重要的是要注意,ms 仅指定何时*添加* 回调函数,而不是何时实际执行它。这可能会在很久以后发生,尤其是在事件循环被阻塞的情况下(本章稍后将演示)。
将 ms 设置为零的 setTimeout() 是一种常用的解决方法,可以立即向任务队列添加内容。但是,某些浏览器不允许 ms 低于最小值(Firefox 中为 4 毫秒);如果低于最小值,它们会将其设置*为* 该最小值。
24.2.2 显示 DOM 更改
对于大多数 DOM 更改(尤其是那些涉及重新布局的更改),显示不会立即更新。“布局每 16 毫秒刷新一次”(@bz_moz),并且必须有机会通过事件循环运行。
有一些方法可以协调频繁的 DOM 更新与浏览器,以避免与其布局节奏发生冲突。有关详细信息,请参阅 requestAnimationFrame() 的文档。
24.2.3 运行至完成语义
JavaScript 具有所谓的运行至完成语义:当前任务总是在执行下一个任务之前完成。这意味着每个任务都可以完全控制所有当前状态,而不必担心并发修改。
让我们看一个例子
setTimeout(function () { // (A)
console.log('Second');
}, 0);
console.log('First'); // (B)
从 A 行开始的函数立即添加到任务队列中,但在当前代码段完成后才执行(特别是 B 行!)。这意味着此代码的输出将始终是
24.2.4 阻塞事件循环
正如我们所见,每个选项卡(在某些浏览器中,是整个浏览器)都由一个进程管理——用户界面和所有其他计算。这意味着您可以通过在该进程中执行长时间运行的计算来冻结用户界面。以下代码演示了这一点。
<a id="block" href="">Block for 5 seconds</a>
<p>
<button>This is a button</button>
<div id="statusMessage"></div>
<script>
document.getElementById('block')
.addEventListener('click', onClick);
function onClick(event) {
event.preventDefault();
setStatusMessage('Blocking...');
// Call setTimeout(), so that browser has time to display
// status message
setTimeout(function () {
sleep(5000);
setStatusMessage('Done');
}, 0);
}
function setStatusMessage(msg) {
document.getElementById('statusMessage').textContent = msg;
}
function sleep(milliseconds) {
var start = Date.now();
while ((Date.now() - start) < milliseconds);
}
</script>
每当单击开头的链接时,都会触发函数 onClick()。它使用——同步——sleep() 函数阻塞事件循环五秒钟。在这五秒钟内,用户界面无法工作。例如,您无法单击“简单按钮”。
24.2.5 避免阻塞
您可以通过两种方式避免阻塞事件循环
首先,您不要在主进程中执行长时间运行的计算,而是将它们移至另一个进程。这可以通过 Worker API 来实现。
其次,您不会(同步)等待长时间运行的计算(您在 Worker 进程中的算法、网络请求等)的结果,而是继续事件循环并让计算在完成后通知您。事实上,您在浏览器中通常甚至没有选择,必须以这种方式做事。例如,没有内置的方法可以同步休眠(就像之前实现的 sleep() 那样)。相反,setTimeout() 允许您异步休眠。
下一节将解释异步等待结果的技术。
24.3 异步接收结果
异步接收结果的两种常见模式是:事件和回调函数。
24.3.1 通过事件异步获取结果
在这种异步接收结果的模式中,您为每个请求创建一个对象,并为其注册事件处理程序:一个用于成功的计算,另一个用于处理错误。以下代码显示了它如何与 XMLHttpRequest API 一起工作
var req = new XMLHttpRequest();
req.open('GET', url);
req.onload = function () {
if (req.status == 200) {
processData(req.response);
} else {
console.log('ERROR', req.statusText);
}
};
req.onerror = function () {
console.log('Network Error');
};
req.send(); // Add request to task queue
请注意,最后一行实际上并没有执行请求,而是将其添加到任务队列中。因此,您也可以在设置 onload 和 onerror 之前,在 open() 之后立即调用该方法。由于 JavaScript 的运行至完成语义,事情的工作方式相同。
24.3.1.1 隐式请求
浏览器 API IndexedDB 具有一种稍微特殊的事件处理风格
var openRequest = indexedDB.open('test', 1);
openRequest.onsuccess = function (event) {
console.log('Success!');
var db = event.target.result;
};
openRequest.onerror = function (error) {
console.log(error);
};
您首先创建一个请求对象,并向其中添加用于接收结果通知的事件侦听器。但是,您不需要显式地将请求排队,这由 open() 完成。它在当前任务完成后执行。这就是为什么您可以在调用 open() *之后*(实际上是必须)注册事件处理程序的原因。
如果您习惯于多线程编程语言,这种处理请求的风格可能看起来很奇怪,就好像它很容易出现竞争条件一样。但是,由于运行至完成,事情总是安全的。
24.3.1.2 事件不适用于单个结果
如果您多次接收结果,这种处理异步计算结果的风格是可以的。但是,如果只有一个结果,那么冗长就会成为一个问题。对于这种情况,回调函数已经变得流行起来。
24.3.2 通过回调函数异步获取结果
如果您通过回调函数处理异步结果,则将回调函数作为尾随参数传递给异步函数或方法调用。
以下是 Node.js 中的一个示例。我们通过对 fs.readFile() 的异步调用读取文本文件的内容
// Node.js
fs.readFile('myfile.txt', { encoding: 'utf8' },
function (error, text) { // (A)
if (error) {
// ...
}
console.log(text);
});
如果 readFile() 成功,则 A 行中的回调函数将通过参数 text 接收结果。如果失败,则回调函数将通过其第一个参数获取错误(通常是 Error 的实例或子构造函数)。
经典函数式编程风格的相同代码如下所示
// Functional
readFileFunctional('myfile.txt', { encoding: 'utf8' },
function (text) { // success
console.log(text);
},
function (error) { // failure
// ...
});
24.3.3 延续传递风格
使用回调函数的编程风格(尤其是在前面所示的函数式风格中)也称为*延续传递风格*(CPS),因为下一步(*延续*)是作为参数显式传递的。这使得被调用的函数可以更好地控制接下来发生的事情以及何时发生。
以下代码说明了 CPS
console.log('A');
identity('B', function step2(result2) {
console.log(result2);
identity('C', function step3(result3) {
console.log(result3);
});
console.log('D');
});
console.log('E');
// Output: A E B D C
function identity(input, callback) {
setTimeout(function () {
callback(input);
}, 0);
}
对于每个步骤,程序的控制流都在回调函数内部继续。这会导致函数嵌套,有时被称为*回调地狱*。但是,您通常可以避免嵌套,因为 JavaScript 的函数声明是被*提升的*(它们的定义在其作用域的开头进行评估)。这意味着您可以提前调用并在程序的后面调用定义的函数。以下代码使用提升来扁平化前面的示例。
console.log('A');
identity('B', step2);
function step2(result2) {
// The program continues here
console.log(result2);
identity('C', step3);
console.log('D');
}
function step3(result3) {
console.log(result3);
}
console.log('E');
24.3.4 在 CPS 中组合代码
在正常的 JavaScript 风格中,您可以通过以下方式组合代码片段
- 将它们一个接一个地放置。这是显而易见的,但提醒自己,以正常风格连接代码是顺序组合,这一点很好。
- 数组方法,例如
map()、filter()和forEach() - 循环,例如
for和while
库 Async.js 提供了组合器,让您可以在 CPS 中使用 Node.js 风格的回调函数执行类似的操作。在以下示例中,它用于加载三个文件的内容,这些文件的名称存储在一个数组中。
var async = require('async');
var fileNames = [ 'foo.txt', 'bar.txt', 'baz.txt' ];
async.map(fileNames,
function (fileName, callback) {
fs.readFile(fileName, { encoding: 'utf8' }, callback);
},
// Process the result
function (error, textArray) {
if (error) {
console.log(error);
return;
}
console.log('TEXTS:\n' + textArray.join('\n----\n'));
});
24.3.5 回调函数的优缺点
使用回调函数会导致截然不同的编程风格,即 CPS。CPS 的主要优点是其基本机制易于理解。但也有缺点
- 错误处理变得更加复杂:现在有两种报告错误的方式——通过回调函数和通过异常。您必须小心地将两者正确组合。
- 不太优雅的签名:在同步函数中,输入(参数)和输出(函数结果)之间有明确的关注点分离。在使用回调函数的异步函数中,这些关注点是混合的:函数结果无关紧要,一些参数用于输入,另一些参数用于输出。
- 组合更复杂:因为关注点“输出”出现在参数中,所以通过组合器组合代码更加复杂。
Node.js 风格的回调函数有三个缺点(与函数式风格的回调函数相比)
- 使用
if语句进行错误处理会增加代码的冗余度。 - 复用错误处理程序更加困难。
- 提供默认错误处理程序也更加困难。如果您调用一个函数并且不想编写自己的处理程序,那么默认错误处理程序就很有用。如果调用者没有指定处理程序,函数也可以使用它。
24.4 展望未来
下一章将介绍 Promise 和 ES6 Promise API。Promise 的底层机制比回调函数更复杂。作为交换,它们带来了一些显著的优势,并消除了前面提到的回调函数的大多数缺点。
24.5 扩展阅读
[1] Philip Roberts 的“救命,我被困在事件循环里了”(视频)。
[2] HTML 规范中的“事件循环”。
[3] Axel Rauschmayer 的“JavaScript 中的异步编程和延续传递风格”。