19 Unicode – 简介(进阶)
- 19.1 代码点与代码单元
- 19.1.1 代码点
- 19.1.2 Unicode 代码点编码:UTF-32、UTF-16、UTF-8
- 19.2 Web 开发中使用的编码:UTF-16 和 UTF-8
- 19.2.1 源代码内部:UTF-16
- 19.2.2 字符串:UTF-16
- 19.2.3 文件中的源代码:UTF-8
- 19.3 字素簇 – 真正的字符
- 19.3.1 字素簇与字形
Unicode 是一种用于表示和管理世界上大多数书写系统的文本的标准。几乎所有处理文本的现代软件都支持 Unicode。该标准由 Unicode 协会维护。该标准每年都会发布新版本(包含新的表情符号等)。Unicode 1.0.0 版本于 1991 年 10 月发布。
19.1 代码点与代码单元
理解 Unicode 的两个关键概念
- 代码点是表示 Unicode 文本原子部分的数字。它们中的大多数表示可见符号,但它们也可以具有其他含义,例如指定符号的某个方面(字母的重音符号、表情符号的肤色等)。
- 代码单元是用于编码代码点以存储或传输 Unicode 文本的数字。一个或多个代码单元编码一个代码点。每个代码单元的大小相同,具体取决于所使用的编码格式。最流行的格式 UTF-8 具有 8 位代码单元。
19.1.1 代码点
第一版 Unicode 具有 16 位代码点。从那时起,字符数量大幅增加,代码点的大小扩展到 21 位。这 21 位被划分为 17 个平面,每个平面 16 位
- 平面 0:基本多文种平面 (BMP),0x0000–0xFFFF
- 包含几乎所有现代语言的字符(拉丁字符、亚洲字符等)和许多符号。
- 平面 1:辅助多文种平面 (SMP),0x10000–0x1FFFF
- 支持历史书写系统(例如,埃及象形文字和楔形文字)和其他现代书写系统。
- 支持表情符号和许多其他符号。
- 平面 2:辅助表意平面 (SIP),0x20000–0x2FFFF
- 包含其他 CJK(中文、日文、韩文)表意文字。
- 平面 3–13:未分配
- 平面 14:辅助专用平面 (SSP),0xE0000–0xEFFFF
- 包含非图形字符,例如标签字符和字形变体选择器。
- 平面 15–16:辅助专用区域 (S PUA A/B),0x0F0000–0x10FFFF
- 可供 ISO 和 Unicode 协会以外的各方分配字符。未标准化。
平面 1-16 称为辅助平面或星形平面。
让我们检查几个字符的代码点
> 'A'.codePointAt(0).toString(16)
'41'
> 'ü'.codePointAt(0).toString(16)
'fc'
> 'π'.codePointAt(0).toString(16)
'3c0'
> '🙂'.codePointAt(0).toString(16)
'1f642'代码点的十六进制数告诉我们,前三个字符位于平面 0(16 位以内),而表情符号位于平面 1。
19.1.2 编码 Unicode 代码点:UTF-32、UTF-16、UTF-8
编码代码点的主要方式是三种Unicode 转换格式 (UTF):UTF-32、UTF-16、UTF-8。每种格式末尾的数字表示其代码单元的大小(以位为单位)。
19.1.2.1 UTF-32(Unicode 转换格式 32)
UTF-32 使用 32 位来存储代码单元,每个代码点对应一个代码单元。此格式是唯一使用固定长度编码的格式;所有其他格式都使用不同数量的代码单元来编码单个代码点。
19.1.2.2 UTF-16(Unicode 转换格式 16)
UTF-16 使用 16 位代码单元。它按如下方式编码代码点
BMP(Unicode 的前 16 位)存储在单个代码单元中。
星形平面:BMP 包含 0x10_000 个代码点。鉴于 Unicode 总共有 0x110_000 个代码点,我们仍然需要编码剩余的 0x100_000 个代码点(20 位)。BMP 有两个未分配的代码点范围,提供了必要的存储空间
- 最高有效 10 位(前导代理):0xD800-0xDBFF
- 最低有效 10 位(后导代理):0xDC00-0xDFFF
换句话说,末尾的两个十六进制数字贡献了 8 位。但只有当 BMP 以以下 2 位数字对之一开头时,我们才能使用这 8 位
- D8、D9、DA、DB
- DC、DD、DE、DF
每个代理,我们可以在 4 对之间进行选择,这就是剩余 2 位的来源。
因此,每个 UTF-16 代码单元始终是前导代理、后导代理或编码 BMP 代码点。
以下是两个 UTF-16 编码代码点的示例
- 代码点 0x03C0 (π) 在 BMP 中,因此可以用单个 UTF-16 代码单元表示:0x03C0。
- 代码点 0x1F642 (
🙂) 在星形平面中,由两个代码单元表示:0xD83D 和 0xDE42。
19.1.2.3 UTF-8(Unicode 转换格式 8)
UTF-8 具有 8 位代码单元。它使用 1–4 个代码单元来编码一个代码点
| 代码点 | 代码单元 |
|---|---|
| 0000–007F | 0bbbbbbb(7 位) |
| 0080–07FF | 110bbbbb,10bbbbbb(5+6 位) |
| 0800–FFFF | 1110bbbb,10bbbbbb,10bbbbbb(4+6+6 位) |
| 10000–1FFFFF | 11110bbb,10bbbbbb,10bbbbbb,10bbbbbb(3+6+6+6 位) |
注意
- 每个代码单元的位前缀告诉我们
- 它是一系列代码单元中的第一个吗?如果是,后面会有多少个代码单元?
- 它是一系列代码单元中的第二个或之后的代码单元吗?
- 0000–007F 范围内的字符映射与 ASCII 相同,这在一定程度上实现了与旧软件的向后兼容性。
三个例子
| 字符 | 代码点 | 代码单元 |
|---|---|---|
| A | 0x0041 | 01000001 |
| π | 0x03C0 | 11001111, 10000000 |
🙂 |
0x1F642 | 11110000, 10011111, 10011001, 10000010 |
19.2 Web 开发中使用的编码:UTF-16 和 UTF-8
Web 开发中使用的 Unicode 编码格式是:UTF-16 和 UTF-8。
19.2.1 源代码内部:UTF-16
ECMAScript 规范在内部将源代码表示为 UTF-16。
19.2.2 字符串:UTF-16
JavaScript 字符串中的字符基于 UTF-16 代码单元
> const smiley = '🙂';
> smiley.length
2
> smiley === '\uD83D\uDE42' // code units
true有关 Unicode 和字符串的更多信息,请参阅§20.7 “文本的原子:代码点、JavaScript 字符、字素簇”。
19.2.3 文件中的源代码:UTF-8
如今,HTML 和 JavaScript 几乎总是编码为 UTF-8。
例如,这就是 HTML 文件现在通常的开头方式
<!doctype html>
<html>
<head>
<meta charset="UTF-8">
···对于在 Web 浏览器中加载的 HTML 模块,标准编码也是 UTF-8。
19.3 字素簇 – 真正的字符
当我们考虑到世界上的各种书写系统时,字符的概念变得非常复杂。这就是为什么有几个不同的 Unicode 术语都以某种方式表示“字符”:代码点、字素簇、字形等。
在 Unicode 中,代码点是文本的原子部分。
但是,字素簇最接近于屏幕或纸张上显示的符号。它被定义为“一个水平可分割的文本单元”。因此,官方 Unicode 文档也将其称为用户感知字符。编码一个字素簇需要一个或多个代码点。
例如,梵文kshi由 4 个代码点编码。我们使用Array.from()将字符串拆分为包含代码点的数组(有关详细信息,请参阅§20.7.1 “使用代码点”)

旗帜表情符号也是字素簇,由两个代码点组成——例如,日本国旗
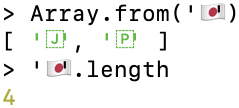
19.3.1 字素簇与字形
符号是一个抽象概念,是书面语言的一部分
- 它在计算机内存中由一个字素簇表示——一个或多个数字(代码点)的序列。
- 它通过字形绘制在屏幕上。字形是一个图像,通常存储在字体中。可以使用多个字形来绘制单个符号——例如,符号“é”可以通过组合字形“e”和字形“´”来绘制。
概念与其表示之间的区别很微妙,在谈论 Unicode 时可能会变得模糊。
![]() 更多关于字素簇的信息
更多关于字素簇的信息
有关更多信息,请参阅 Manish Goregaokar 的“让我们停止将含义归因于代码点”。
![]() 测验
测验
请参阅测验应用程序。