27. 尾调用优化
ECMAScript 6 提供了*尾调用优化*,您可以使用它进行一些函数调用而不会增加调用堆栈。本章解释了它的工作原理及其带来的好处。
**警告:**尽管尾调用优化是语言规范的一部分,但 它不受许多引擎支持,而且这种情况可能永远不会改变。
- 27.1. 什么是尾调用优化?
- 27.1.1. 正常执行
- 27.1.2. 尾调用优化
- 27.2. 检查函数调用是否处于尾部位置
- 27.2.1. 表达式中的尾调用
- 27.2.2. 语句中的尾调用
- 27.2.3. 尾调用优化只能在严格模式下进行
- 27.2.4. 陷阱:单独的函数调用永远不会处于尾部位置
- 27.3. 尾递归函数
- 27.3.1. 尾递归循环
27.1 什么是尾调用优化?
粗略地说,每当函数最后要做的事情是调用另一个函数时,后者就不需要返回到它的调用者。因此,不需要在调用堆栈上存储任何信息,函数调用更像是一个 goto(跳转)。这种调用称为*尾调用*;不增加堆栈称为*尾调用优化* (TCO)。
让我们看一个例子来更好地理解 TCO。我将首先解释它如何在没有 TCO 的情况下执行,然后解释如何在有 TCO 的情况下执行。
function id(x) {
return x; // (A)
}
function f(a) {
const b = a + 1;
return id(b); // (B)
}
console.log(f(2)); // (C)
27.1.1 正常执行
假设有一个 JavaScript 引擎,它通过将局部变量和返回地址存储在堆栈上来管理函数调用。这样的引擎将如何执行代码?
**步骤 1.** 最初,堆栈上只有全局变量 id 和 f。

堆栈条目的块编码当前作用域的状态(局部变量,包括参数),称为*堆栈帧*。
**步骤 2.** 在 C 行,调用 f():首先,将要返回的位置保存在堆栈上。然后分配 f 的参数,执行跳转到其主体。堆栈现在如下所示。
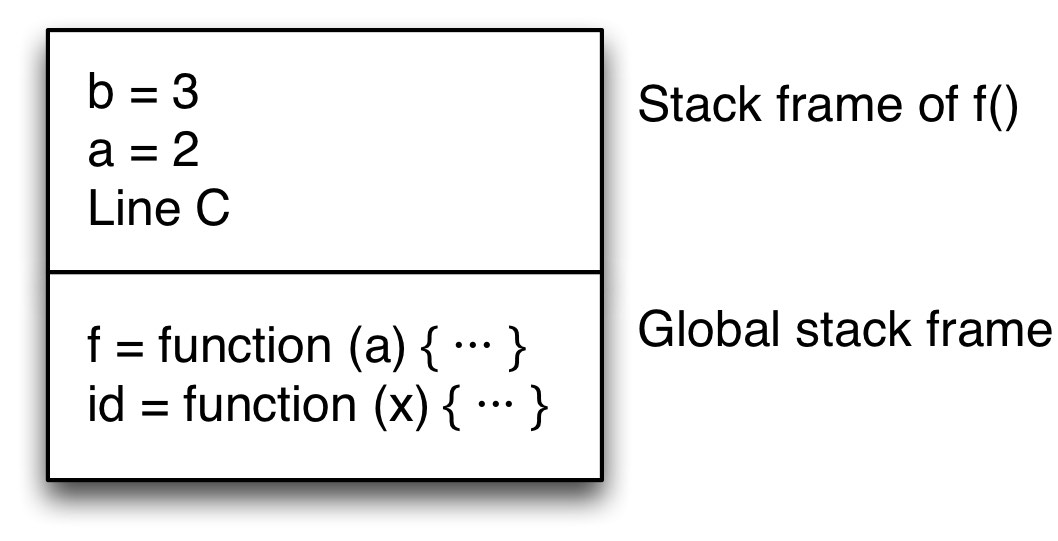
堆栈上现在有两个帧:一个用于全局作用域(底部),一个用于 f()(顶部)。 f 的堆栈帧包括返回地址,C 行。
**步骤 3.** 在 B 行调用 id()。同样,会创建一个堆栈帧,其中包含返回地址和 id 的参数。
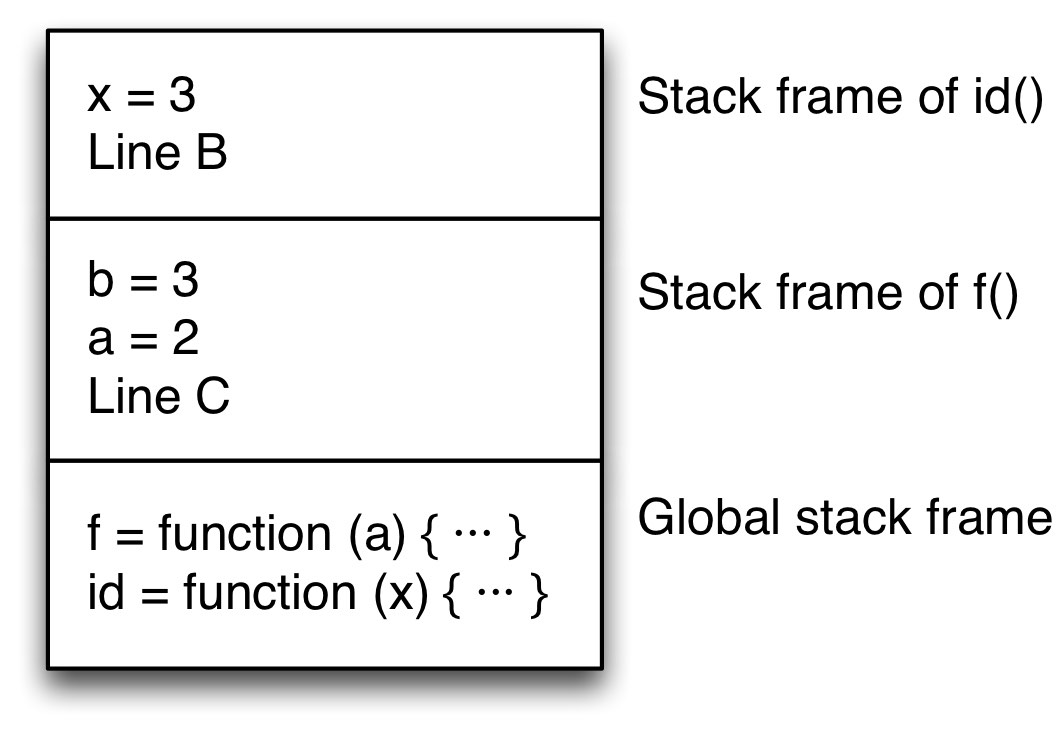
**步骤 4.** 在 A 行,返回结果 x。 id 的堆栈帧被移除,执行跳转到返回地址,B 行。(处理返回值的方法有很多种。两种常见的解决方案是将结果留在堆栈上或将其移交给寄存器。我在这里忽略了执行的这一部分。)
堆栈现在如下所示
**步骤 5.** 在 B 行,将 id 返回的值返回给 f 的调用者。同样,最顶层的堆栈帧被移除,执行跳转到返回地址,C 行。
**步骤 6.** C 行接收值 3 并将其记录下来。
27.1.2 尾调用优化
function id(x) {
return x; // (A)
}
function f(a) {
const b = a + 1;
return id(b); // (B)
}
console.log(f(2)); // (C)
如果您查看上一节,那么有一个步骤是不必要的——步骤 5。B 行中发生的一切都是将 id() 返回的值传递给 C 行。理想情况下,id() 可以自己完成,并且可以跳过中间步骤。
我们可以通过以不同的方式实现 B 行中的函数调用来实现这一点。在调用发生之前,堆栈如下所示。
如果我们检查调用,我们会发现它是 f() 中的最后一个动作。一旦 id() 完成,f() 执行的唯一剩余动作就是将 id 的结果传递给 f 的调用者。因此,不再需要 f 的变量,并且可以在进行调用之前移除其堆栈帧。赋予 id() 的返回地址是 f 的返回地址,C 行。在 id() 的执行过程中,堆栈如下所示
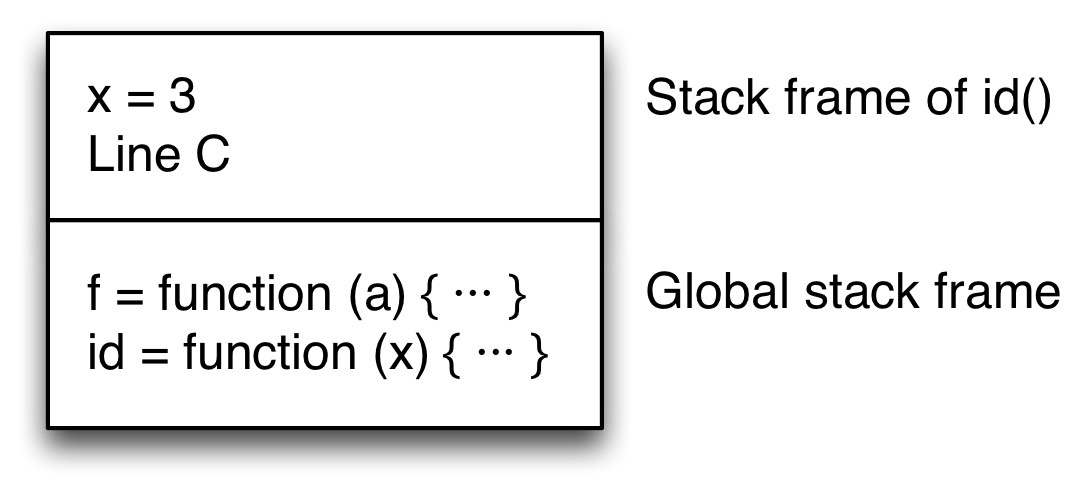
然后 id() 返回值 3。您可以说它是为 f() 返回该值的,因为它将其传输到 f 的调用者,C 行。
让我们回顾一下:B 行中的函数调用是一个尾调用。这样的调用可以在堆栈不增长的情况下完成。要确定函数调用是否是尾调用,我们必须检查它是否处于*尾部位置*(即函数中的最后一个动作)。下一节将解释如何做到这一点。
27.2 检查函数调用是否处于尾部位置
我们刚刚了解到尾调用是可以更有效地执行的函数调用。但是什么算作尾调用呢?
首先,调用函数的方式无关紧要。如果以下调用出现在尾部位置,则都可以对其进行优化
- 函数调用:
func(···) - 分派方法调用:
obj.method(···) - 通过
call()进行的直接方法调用:func.call(···) - 通过
apply()进行的直接方法调用:func.apply(···)
27.2.1 表达式中的尾调用
箭头函数可以将表达式作为主体。因此,对于尾调用优化,我们必须找出函数调用在表达式中的尾部位置。只有以下表达式可以包含尾调用
- 条件运算符 (
? :) - 逻辑或运算符 (
||) - 逻辑与运算符 (
&&) - 逗号运算符 (
,)
让我们看看它们每一个的例子。
27.2.1.1 条件运算符 (? :)
const a = x => x ? f() : g();
f() 和 g() 都处于尾部位置。
27.2.1.2 逻辑或运算符 (||)
const a = () => f() || g();
f() 不在尾部位置,但 g() 在尾部位置。要了解原因,请查看以下代码,它等效于前面的代码
const a = () => {
const fResult = f(); // not a tail call
if (fResult) {
return fResult;
} else {
return g(); // tail call
}
};
逻辑或运算符的结果取决于 f() 的结果,这就是为什么该函数调用不在尾部位置的原因(调用者对其执行的操作不是返回它)。但是,g() 处于尾部位置。
27.2.1.3 逻辑与运算符
const a = () => f() && g();
f() 不在尾部位置,但 g() 在尾部位置。要了解原因,请查看以下代码,它等效于前面的代码
const a = () => {
const fResult = f(); // not a tail call
if (!fResult) {
return fResult;
} else {
return g(); // tail call
}
};
逻辑与运算符的结果取决于 f() 的结果,这就是为什么该函数调用不在尾部位置的原因(调用者对其执行的操作不是返回它)。但是,g() 处于尾部位置。
27.2.1.4 逗号运算符 (,)
const a = () => (f() , g());
f() 不在尾部位置,但 g() 在尾部位置。要了解原因,请查看以下代码,它等效于前面的代码
const a = () => {
f();
return g();
}
27.2.2 语句中的尾调用
对于语句,适用以下规则。
只有这些复合语句可以包含尾调用
- 块(由
{}分隔,带或不带标签) -
if:在“then”子句或“else”子句中。 -
do-while、while、for:在其主体中。 -
switch:在其主体中。 -
try-catch:仅在catch子句中。try子句具有catch子句作为上下文,不能优化掉。 -
try-finally、try-catch-finally:仅在finally子句中,它是其他子句的上下文,不能优化掉。
在所有原子(非复合)语句中,只有 return 可以包含尾调用。所有其他语句都有不能优化掉的上下文。如果 expr 包含尾调用,则以下语句包含尾调用。
return «expr»;
27.2.3 尾调用优化只能在严格模式下进行
在非严格模式下,大多数引擎都具有以下两个属性,允许您检查调用堆栈
-
func.arguments:包含最近一次调用func的参数。 -
func.caller:引用最近调用func的函数。
使用尾调用优化时,这些属性不起作用,因为它们依赖的信息可能已被删除。因此,严格模式禁止这些属性(如语言规范中所述),并且尾调用优化仅在严格模式下有效。
27.2.4 陷阱:单独的函数调用永远不会处于尾部位置
以下代码中的函数调用 bar() 不在尾部位置
function foo() {
bar(); // this is not a tail call in JS
}
原因是 foo() 的最后一个动作不是函数调用 bar(),而是(隐式地)返回 undefined。换句话说,foo() 的行为如下
function foo() {
bar();
return undefined;
}
调用者可以依赖 foo() 始终返回 undefined。如果 bar() 由于尾调用优化而为 foo() 返回结果,那么这将改变 foo 的行为。
因此,如果我们希望 bar() 成为尾调用,我们必须按如下方式更改 foo()。
function foo() {
return bar(); // tail call
}
27.3 尾递归函数
如果函数进行的主要递归调用位于尾部位置,则该函数是*尾递归*。
例如,以下函数不是尾递归的,因为 A 行中的主要递归调用不在尾部位置
function factorial(x) {
if (x <= 0) {
return 1;
} else {
return x * factorial(x-1); // (A)
}
}
factorial() 可以通过尾递归辅助函数 facRec() 实现。A 行中的主要递归调用位于尾部位置。
function factorial(n) {
return facRec(n, 1);
}
function facRec(x, acc) {
if (x <= 1) {
return acc;
} else {
return facRec(x-1, x*acc); // (A)
}
}
也就是说,一些非尾递归函数可以转换为尾递归函数。
27.3.1 尾递归循环
尾调用优化使得通过递归实现循环成为可能,而不会增加堆栈。以下是两个例子。
27.3.1.1 forEach()
function forEach(arr, callback, start = 0) {
if (0 <= start && start < arr.length) {
callback(arr[start], start, arr);
return forEach(arr, callback, start+1); // tail call
}
}
forEach(['a', 'b'], (elem, i) => console.log(`${i}. ${elem}`));
// Output:
// 0. a
// 1. b
27.3.1.2 findIndex()
function findIndex(arr, predicate, start = 0) {
if (0 <= start && start < arr.length) {
if (predicate(arr[start])) {
return start;
}
return findIndex(arr, predicate, start+1); // tail call
}
}
findIndex(['a', 'b'], x => x === 'b'); // 1